DBT and Airbyte complement each other perfectly. DBT enables analysts and engineers to easily and efficiently transform their data in their data warehouse environment, but the data first needs to be present in that environment. This is where Airbyte comes into the picture by enabling those same engineers and analysts to easily and reliably transfer data from their different sources to the data warehouse. When used together, these two open-source powerhouses reduce overall time to insight and propel your organization towards a truly modern data stack.
Airbyte
Airbyte provides an easy-to-use platform for data extraction and ingestion with a mission to make data integration pipelines a commodity. It’s open-source by nature and with the ability to self-host your data will no longer be processed by a third party, making security concerns a thing of the past.
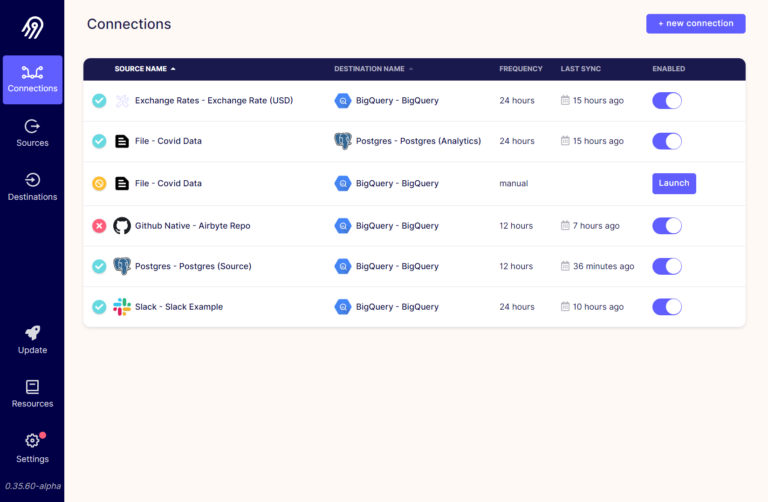
Airbyte comes with an intuitive webinterface to define sources and destinations, as well as the option to seamlessly create connections between any source and any destination. There are a plethora of connectors available with even more coming up. Airbyte even provides the option to create your very own connector from scratch using their python or java templates.
Defining either a source or destination was never easier since Airbyte has an indepth explanation tailored to the platform you’re trying to link, as well as a connection test that will make sure your settings are valid.
When creating a connection between any source and destination, you can choose to either manually sync or have it scheduled. Airbyte provides over 150 connectors, from which a select few have support for CDC; Postgres, MySQL, MSSQL with support for Oracle DB coming soon. Every connection has the option to perform data normalisation before loading your data into its destination, or create your own transformations using a custom DBT-project.
DBT
DBT, shorthand for Data Build Tool, performs the T (Transform) of ETL and does not support extract nor load operations. In essence, DBT makes it possible for data engineers to create data transformations by simply writing select-statements. The use of these SQL-based transformations is one of the main powers of DBT, no specialty programming knowledge is needed.
The power of DBT comes largely in their usage of jinja to evolve SQL into a functional programming language including conditions, loops, as well as storing and passing variables.
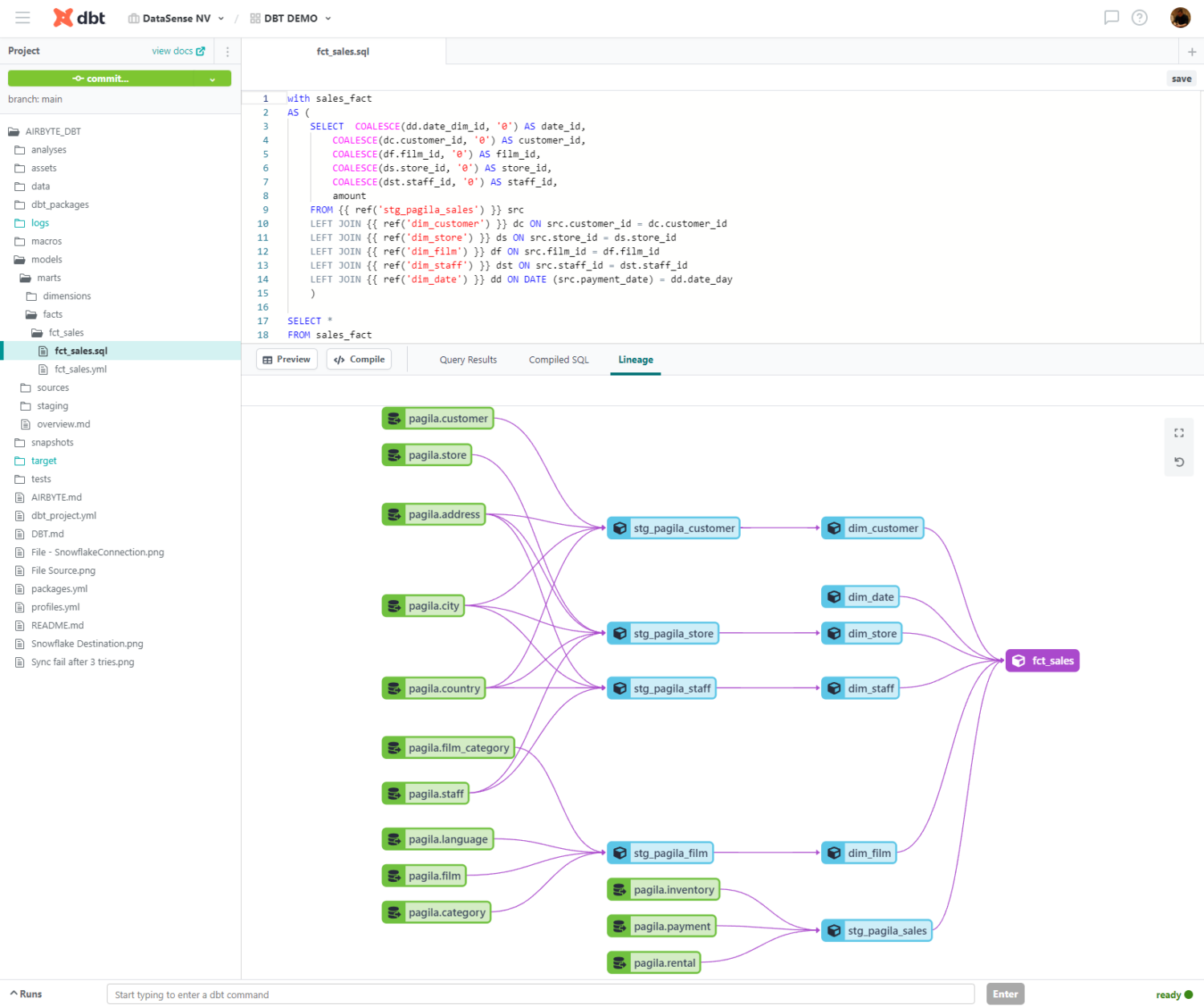
A DBT project follows a predetermined structure to define models and configure the connection to your data warehouse as well as automate macros, analyses, testing and automatically generated documentation with table level data lineage. Besides providing a standard project structure, DBT also provides custom commands such as ‘dbt run’, ‘dbt test’, ‘dbt docs generate’, etc.. DBT integrates software engineering best practices, like DevOps principles, into a data warehousing context.
While DBT is open-source software, they also provide a cloud solution with some extra features that can come in handy while developing data transformations. There is the option to preview generated SQL before running that query on your data, as well as the option to see the data lineage for the table or view that will be created.