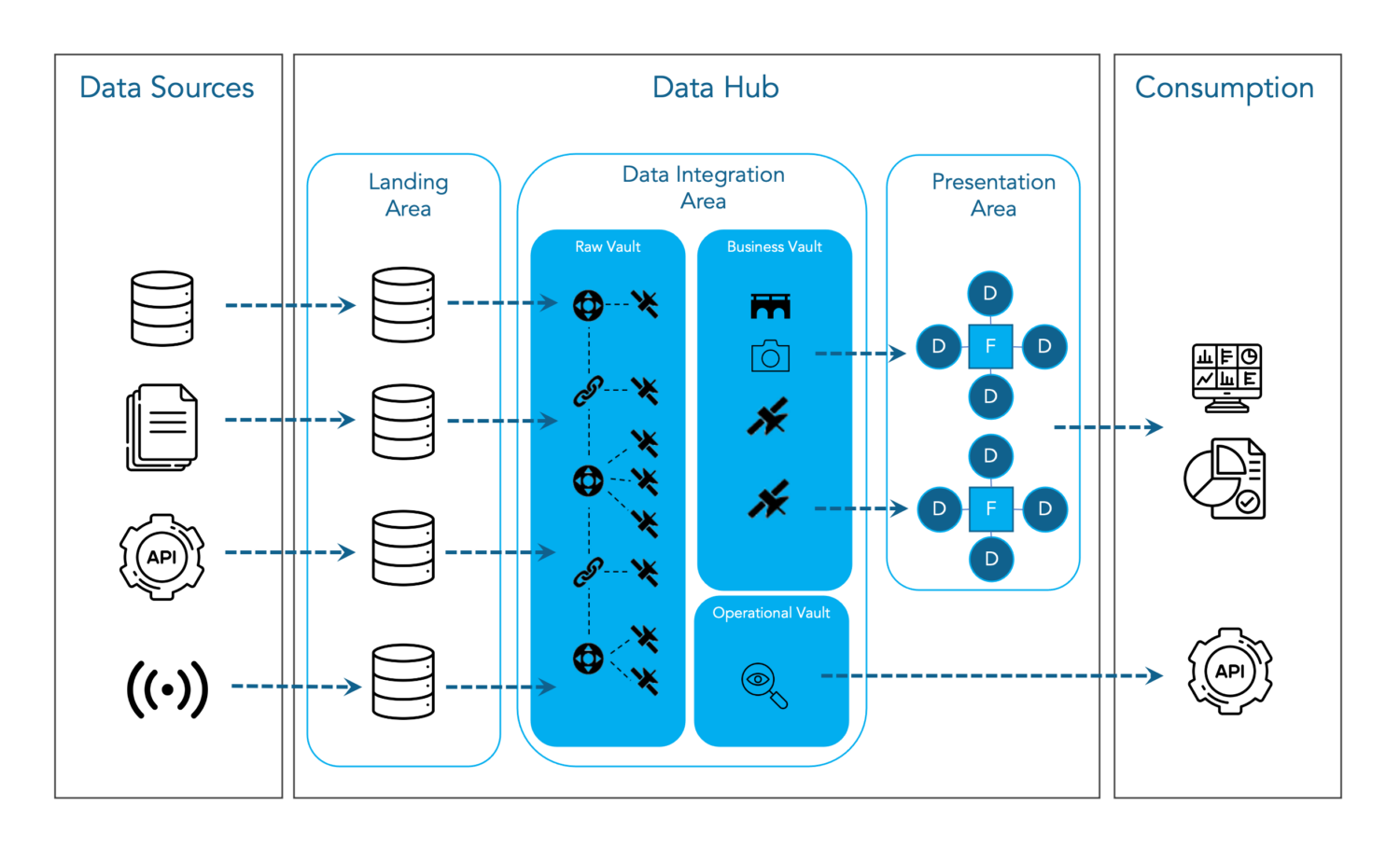
At DataSense, we believe building a data platform always starts with a well-defined plan. Custom-built solutions tend to be difficult to maintain and are especially not future proof. Therefore, we like to work with an open standard, namely Data Vault 2.0. This standard combines methodology with a modelling approach and architectural guidelines.
Automation
In Data Vault 2.0, the implementation of business logic is separated from the integration and historization of data. The so-called Raw Data Vault layer combines data from different source systems into a set of entities, without changing the data. These entities always have a similar structure. As a result, it is possible to automate the development process of the table structures and data pipelines based on repeatable patterns.
- Lets you adapt to changes quickly
- Reduces manual work
- Shortens the time to market
- Reduces the chance of faulty code
Vaultspeed
For the automation of a Data Vault 2.0 data platform, we opt for Vaultspeed, currently the only certified automation tool. With Vaultspeed you can read metadata of different source systems, configure settings and model your data vault. Based on those configurations, the tool will generate code that you can deploy on your specified target platform.
Main features Vaultspeed
In this blogpost, we will have a look at four main characteristics of Vaultspeed, namely the wide support of source and target systems, ETL/ELT and orchestration tool integration and graphical editing of your models.
Vaultspeed supports all the most popular source and target technologies natively. For source systems, we can think of database systems like PostgreSQL, MS SQL Server and Oracle, but also files like CSV or JSON. Snowflake, Azure Synapse and Google BigQuery constitute some of the possible target systems. Via a separate license, one can obtain the extended Vaultspeed agent, which gives you the possibility to add any JDBC driver.
Vaultspeed is in fact a code generation tool. They focus on delivering the code that is needed to build a Data Vault 2.0 model. For the orchestration of the loading process of the data platform, it relies on integrations with third party tools. Apache Airflow and Azure Data Factory are natively supported, which means Vaultspeed can generate the necessary DAGs (for Airflow) and pipelines (for ADF). On top of that, the tool has the possibility to provide your ELT code not just in SQL but also in code for Talend, ODI or Matillion.
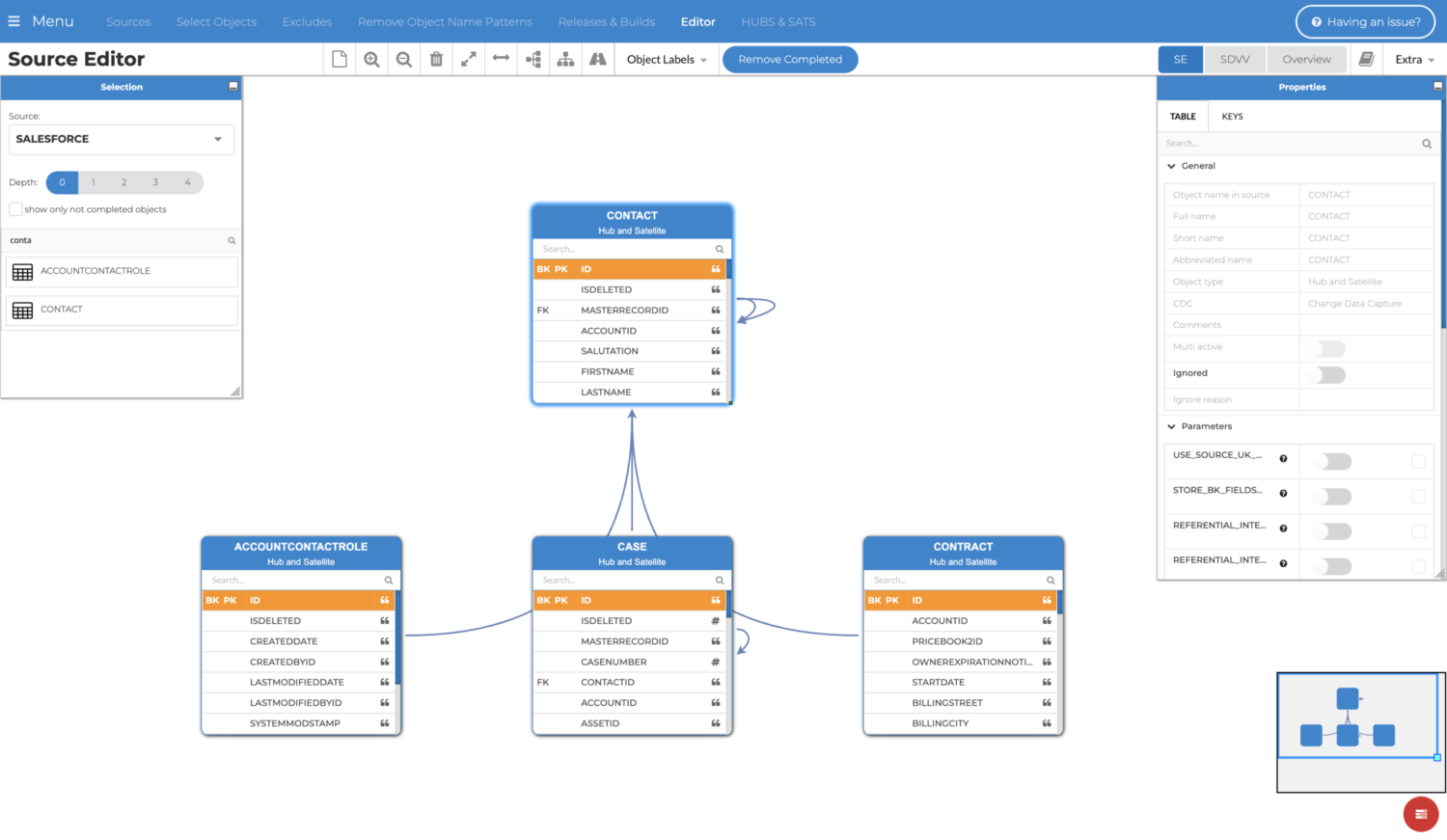
The tool is characterized by its user-friendly interface. The following image shows the source graphical editor. This is the place where you can edit the settings of a source system. Business keys, object types, foreign keys, primary keys, different parameter, business names, and much more can be configured.
Vaultspeed is a template based automation tool. This means that Vaultspeed guarantees the quality of generated code based on their templates. Vaultspeed also allows you to make your own templates with Vaultspeed Studio.
Vaultspeed Studio lets you automate logic beyond Raw Data Vault borders — to apply the same company-specific exchange rates everywhere, for example. Or to create business views that put a GDPR protective layer on top of your raw data.