
Let’s talk about dbt (Data Build Tool) and Databricks. In our previous posts we have already talked about dbt and Databricks on their own, but what if we were to use these tools together? In this blog post, we’ll explore why the use of dbt and Databricks together is a great choice and will simplify your Data Lakehouse / pipelines.
// DATABRICKS
Before we can talk about dbt and Databricks together, let’s learn a little more about Databricks. Databricks is an end-to-end unified platform that can be used for data processing, machine learning and artificial intelligence. To do all this, Databricks gives you the option of using SQL, Python, Scala or R to store, transform and display your data.
The place where this data is stored is the data lakehouse, a bridge between the old data warehouse, made for structured data, and the newer data lake, designed for structured, semi-structured and unstructured data. If you’re reading this, you’re probably thinking, “Why not use the data lake, it has structured data and more?” But the problem with the data lake is that it lacks data quality, which is a key advantage of the data warehouse.
This is where Delta Lake comes into the picture. Delta Lake is an open-source storage layer that brings reliability to your data lake by adding a transactional storage layer over your data. This also allows you to handle batch and streaming data in the same way.
You can use this data in your own workspace or in a shared workspace. One of the main advantages of using Databricks in a team is the shared workspaces and the fact that everyone can access the same data at the same time. This is also known as a single source of truth. This single source of truth simplifies the architecture, which in turn means a reduction in cost and complexity.
// DBT
For those who haven’t read our previous blog posts on dbt, here’s a quick reminder of what dbt is. dbt or Data Build Tool is a powerful SQL-based open-source tool that helps automate table creation, testing and data documentation. dbt does this by creating tables with SELECT statements and automatically generating the corresponding DDL (Data Definition Language) like a CREATE TABLE statement. When testing in dbt, you have the option of running either schema tests or data tests.
Once the code for the tables and tests has been created, it is time to deploy the data. This is made easy with commands such as ‘dbt run’ and ‘dbt test’ when testing the code, and ‘dbt build’ when deploying. These commands can be used in both the dbt Core and dbt Cloud versions.
Although most of the features of dbt remain the same for Cloud or Core, there are some differences. If you want to know more about these differences, I recommend you read our other blog post about dbt, “dbt – Core vs Cloud“. For the rest of this post, we are going to focus on dbt Cloud as it ties in perfectly with our cloud story with Databricks.
The execution of a job in dbt is usually done on a regular basis in the production environment. In this job, you can select the commands that are to be run and whether or not you want to generate documentation.
One of the key features of dbt is that you can use Git directly to version control your code. You won’t be able to edit files in the main branch on dbt Cloud. You have to create a separate branch if you want to make any changes, which is seen as a best practice. This is to ensure that no broken code is created on the main branch, which would automatically break the data pipeline.
// THE SYNERGY OF DATABRICKS & DBT
We’ve had a look at Databricks and dbt. Let’s talk about why their use together will improve our workflows and data lifecycles. Companies often see the data science teams separated from the data analytics teams. This is what happens when separate business units in a large organisation operate independently of each other, because they have their own goals and priorities.
So how do we make sure that this doesn’t happen? By making sure that all of the data is available to all of them in the same place. This is where one of the strengths of Databricks comes into play. It’s a platform that can be used for machine learning, but also for data storage and transformation. But now that we have our platform to store the data on, we have a different problem to solve. With Databricks, we can use SQL, Python, Scala and R. This is very interesting because it means that we have a wide variety of ways to transform the data.
However, this flexibility may come at a cost to us in the future. Let’s say we want to hire a new Data Scientist who is well-versed in SQL and knows how to use Python. But he or she has no idea how to work with Scala or R. Or maybe we want to move to a different data platform, but parts of our code are written in a language that is not compatible with that other platform. In this case, we would have vendor lock-in, or we would have to do a refactoring of part of our code base, which would cost us time and money.
Our saviour in this situation is dbt. With dbt we are only able to use SQL and a limited amount of Python for Snowflake, Databricks or BigQuery. In other words, dbt immediately standardised our data transformation process. And thanks to dbt, we now also have a way of generating our documentation, which we would otherwise have to do on our own. This documentation is essential as we visualise the data flow and keep all our documentation in a consistent format and up to date.
The medallion architecture is the design pattern of choice for the Data Lakehouse. It consists of three layers, aptly named bronze, silver and gold. To achieve this architecture, we can use dbt to help transform data between these layers.
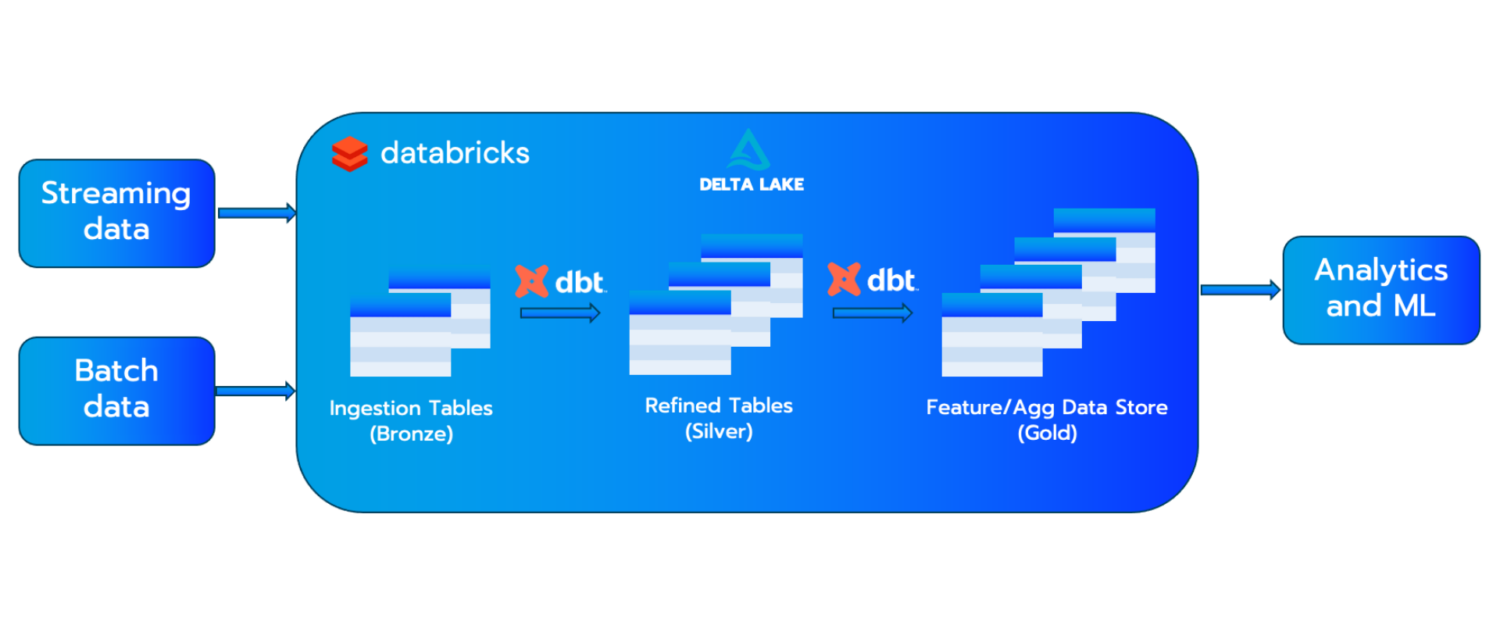
The Medallion architecture is designed to meet the challenges of the data lake. With this architecture, we are incrementally improving the quality of the data as it flows through the different tiers. This provides a clear data lifecycle, from raw data in the bronze tier to curated data in the gold tier.
So now we know why using dbt and Databricks together can improve our data pipeline, but how do we get them to work together?
// HOW TO SETUP A CONNECTION BETWEEN DBT & DATABRICKS
There are two ways to get dbt Cloud connected to Databricks. We can do it manually or we can do it automatically through the Databricks Partner Connect. And with this connection, we will be able to run the dbt Cloud code on a high-performance Databricks platform.
Manual
If we want to configure this connection manually, we can follow the guide provided by dbt here. This is a summary of what is required to set up the connection.
In Databricks:
- A new or existing SQL warehouse
- The “Server Hostname” and “HTTP Path” of this SQL warehouse
- A personal access token
In dbt:
- Choose the project name
- Choose the connection (Databricks)
- Fill in the parameters collected in Databricks
- Choose the Git repository you want to use
Automatic
When we set up the connection with Databricks Partner Connect, a lot of the work will be taken away from us.
Databricks will create the required credentials and set up your environment, while at the same time keeping it secure and governed.
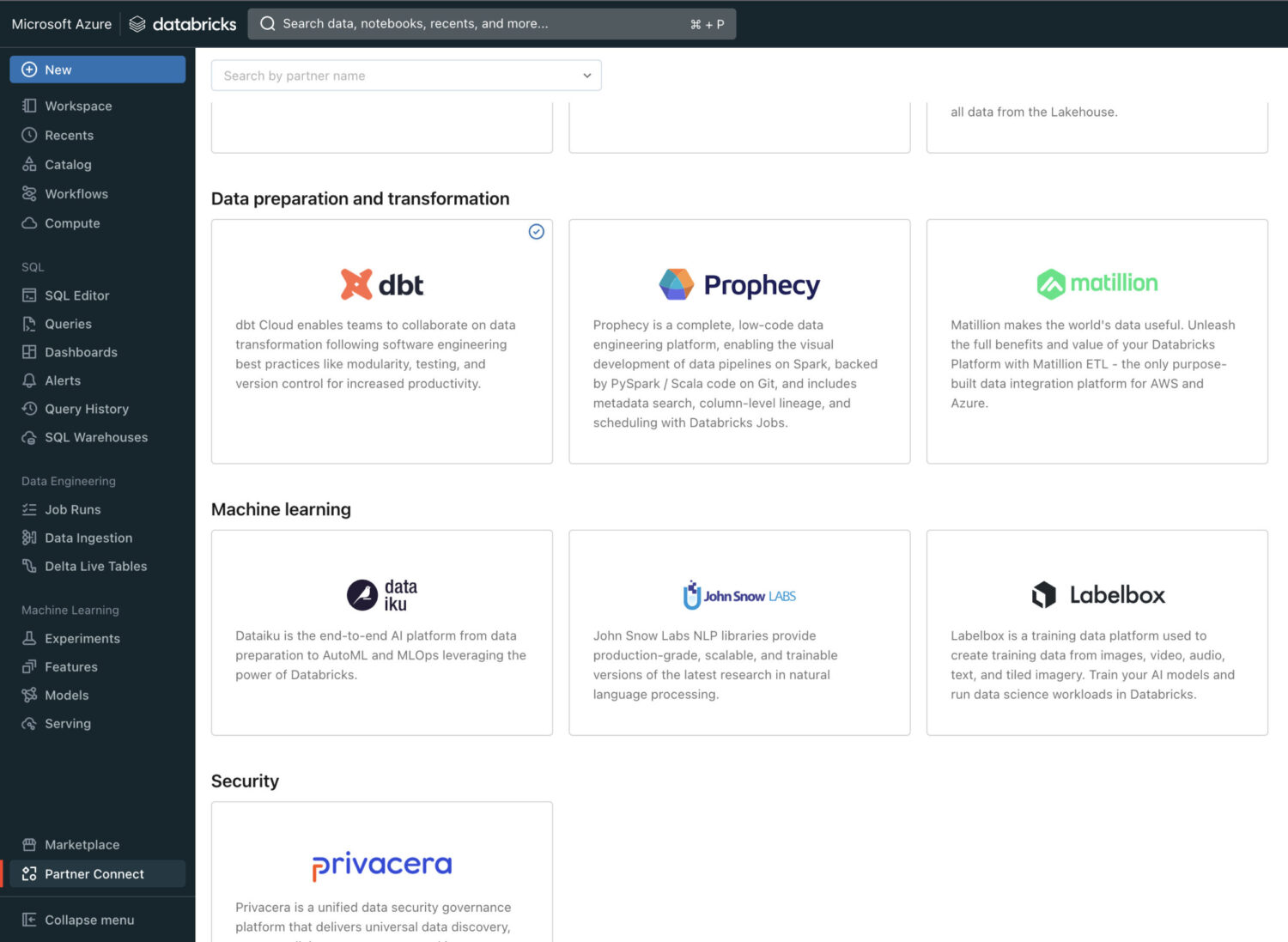
We will again give a short summary of the requirements to set up the connection, but we advise you to consult the official demo video here.
In Databricks:
- Select dbt for the Partner Connect
- Choose a Catalog
- Choose a SQL warehouse or create one if none exists
- Connect to dbt Cloud
In dbt:
- Log into dbt when redirected from Databricks
// CONCLUSION
In summary, integrating dbt with Databricks provides a robust solution for streamlining data workflows and enhancing data lakehouse architectures. This combination leverages Databricks’ versatility in data processing and machine learning with dbt’s SQL-based transformation and documentation capabilities to provide a unified platform.
With the unification of dbt and Databricks, which we have done manually or through the Databricks Partner Connect, we have:
- Improved collaboration between teams by creating a standardised ecosystem for data transformation processes
- Ensured a single source of truth for the entire organisation
This will ensure that we are able to unlock the full potential of our data.


