
Pivotal Greenplum for Advanced Analytics
With Pivotal Greenplum, data professionals can test diverse models in parallel on multi-structured data sets—including machine learning, text, graph, and geo-spatial. Rapidly create and deploy models for complex applications in cybersecurity, predictive maintenance, risk management, fraud detection, and many other areas.
Open-source innovation
Pivotal Greenplum is based on the Open Source PostgreSQL and the Greenplum Database project. It offers optional use-case specific extensions like PostGIS for geospatial analysis, and GPText (based on Apache Tika and Apache Solr) for document extraction, search, and natural language processing. These are pre-integrated to ensure a consistent experience, not a “wild-west,” DIY open-source approach. Instead of depending on expensive proprietary databases, users can benefit from the contributions of a vibrant community of developers.
Greenplum reduces data silos by providing you with a single, scale-out environment for converging analytic and operational workloads, like streaming ingestion. Execute point queries, fast data ingestion, data science exploration, and long-running reporting queries with greater scale and concurrency.
Greenplum Architecture
Greenplum Database is a massively parallel processing (MPP) database server with an architecture specially designed to manage large-scale analytic data warehouses and business intelligence workloads.
MPP (also known as a shared nothing architecture) refers to systems with two or more processors that cooperate to carry out an operation, each processor with its own memory, operating system and disks. Greenplum uses this high-performance system architecture to distribute the load of multi-terabyte data warehouses, and can use all of a system’s resources in parallel to process a query.
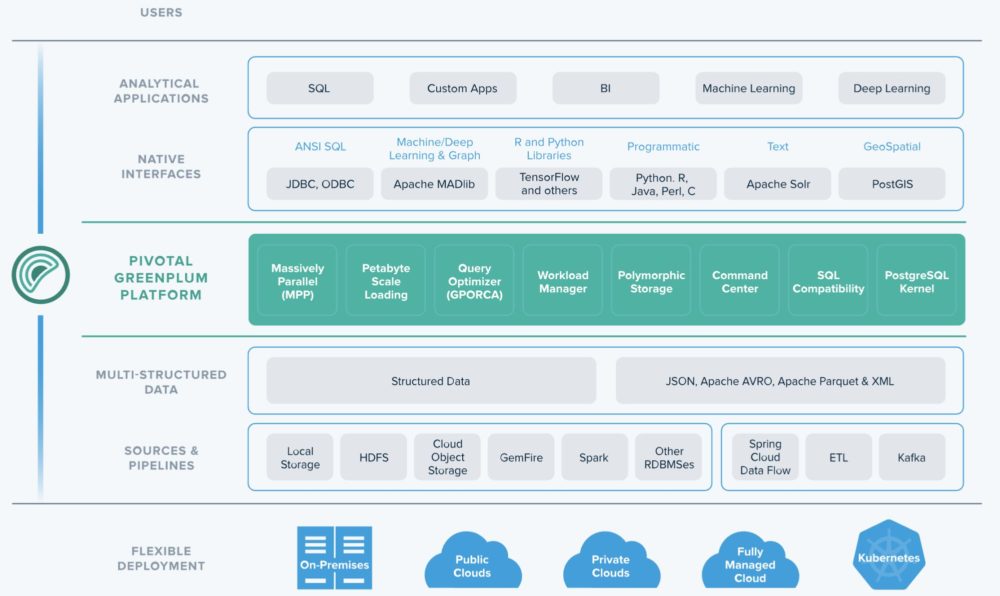
The main benefits of the Greenplum architecture
- It can scale to support more reading operations by adding more data nodes.
- It supports column-oriented table organization, which can be useful for data-warehousing solutions.
- Data compression is supported.
- High-availability features are supported out of the box. It’s possible (and recommended) to add a secondary master that would take over in case a primary master crashes. It’s also possible to add mirrors to the data nodes to prevent data loss.
- In database analytics
Enterprise data science
Designed to run anywhere
Greenplum is designed to run anywhere—on-premises, in public and private clouds, and in modern containerized environments like Kubernetes—for easier installation, operation, and upgrades.