// Solution
Data Lineage
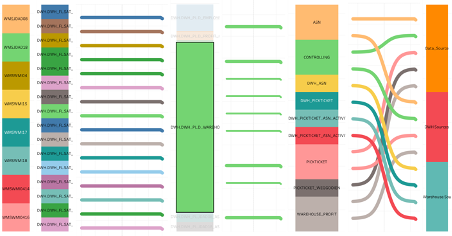
Data lineage describes the complete data life cycle by providing insight in the data flow from start to finish. It uncovers how data flows from the data sources to the data consumers
// Meta data management
Data Lineage
Metadata management is the management of data about other data. It comprises, among other things, data modeling, data governance and metadata administration. In this piece, we will focus on data lineage, a key component in metadata management. Data lineage describes the complete data life cycle by providing insight in the data flow from start to finish. It uncovers how data flows from the data sources to the data consumers. Typically, this journey specifies multiple entities:
- The data provenance
- Sources from which the data is extracted
- Applications (ERP, CRM, …), API’s, Flat files, etc.
- Storage locations
- Temporary or permanent locations of the data
- Data lake, files, data warehouse, etc.
- Transformations
- How is the data processed and moved?
- ETL, streaming, etc.
- Consumption
- How is the data consumed?
- BI applications, API’s, etc.
Use cases
In this section, we cover three popular use cases of data lineage. However, the application of data lineage isn’t limited to these three. Many more applications are possible. At first, it can be used to track the origin of data (‘Upstream’ analysis). A data consumer that is analyzing a report can see from which source system specific data comes and the stages it has gone through. This enables verification of the data that is visible in the report. Secondly, data lineage enables the possibility to perform an impact analysis (‘Downstream’ analysis). A change in a source system table will have an impact later in the chain. Therefore, it is important to be able to find out which entities (e.g. pipelines, processes, information marts, reports, etc.) are impacted. As a result, change management can be performed more efficiently. Thirdly, it benefits data governance. At each stage in the data life cycle, it is known where the data is coming from and where it is going to which has a positive influence on the auditability.Solution
At one of our customers, there is a data warehouse modelled in Data Vault 2.0 with following tool stack:- Snowflake
- Vaultspeed (Data Vault 2.0 automation tool)
- Tableau